Warframe developers provide some crash statistics and describe diagnosing the issue

www.tomshardware.com
Based on information regarding the nature of the most common errors (predominantly things that would hammer the memory subsystem); what mitigations occasionally seem to be working (lower memory clocks, disabling E-cores); the differences between Alder Lake and Raptor Lake; Raptor Lake's short development cycle (less than a year, which is extremely fast); and that Intel has apparently canceled a future high-E-core count
Arrow Lake refresh during development lead me to believe one of the main contributing factors, if not the main issue, is with the ring bus.
The various P-cores, E-core clusters (and their associated L3 cache slices), system agent (which includes the memory controllers), and IGP are all connected by a (dual?) ring bus. Each one of these units needs a ring stop and each ring stop adds a bit of latency. Alder Lake topped out at twelve ring stops and ran the ring around 3.6GHz at stock, with E-cores enabled. Raptor Lake added two ring stops, faster memory support, and simultaneously tried to improve L3 and memory latency, which means a much higher stock ring clock. If the ring and it's associated power planes weren't redesigned to compensate it's not far fetched to think it could be failing earlier than anticipated.
So that's my hypothesis...dramatically more demand placed on the ring bus, combined with higher overall current draw, and higher average temperatures, with cores also pushed to the edge of stability, is resulting in a large fraction of parts being doomed to fail. Abbreviated development time to rush out a stop-gap architecture probably caused Intel to make unwise assumptions about reliability, rather than testing actual samples long enough to get a good feel for in situ failure rates.
Hopefully Intel stands behind their products and takes care of their customers for anyone affected
Last time Intel screwed up and had a major release that had unmitigable defects was with the Pentium III 1.13GHz Coppermine about 24 years ago. Some reviewers noticed problems with their samples in the weeks leading up to launch, which others were eventually able to reproduce. Turned out that a very large portion of 1.13GHz Pentium IIIs weren't stable at 1.13GHz. Third parties had to approach Intel and demonstrate the issue, which caused Intel to halt shipments, try to fix issues via microcode and new guidance to motherboard makers (sound familiar?), only to eventually recall the entire line.
You certainly remember our negative experiences with the 1.13 GHz Pentium III processor that we received for reviewing four weeks ago. We concluded that Intel should consider the retraction of this chip. In a joint venture between us, HardOCP and AnandTech we found out that three different 1.13...
www.tomshardware.com
It's already been a longer process with Raptor Lake, with less meaningful action. I do admit that transient errors and reliability issues are much harder to demonstrate than a clear-cut inability to complete a specific task, but there appears to be months of compelling evidence of issues. A huge number of probably defective samples are out there and Intel is still shipping and selling them.
Mindshare is a fickle thing. Consumers that know they've been screwed over can go from being slavering fanbois to holding equally irrational negative biases long after the fact. Unless Intel is confident there is no intrinsic problem with these parts that would significantly elevate failure rates (a conclusion that would, quite frankly, sound ludicrous at this point), Intel should immediately stop sales, recall all unsold inventory, and start offering replacements with known-good samples, or full refunds, to any owner of any potentially affected parts, no questions asked.

 www.guru3d.com
www.guru3d.com
")
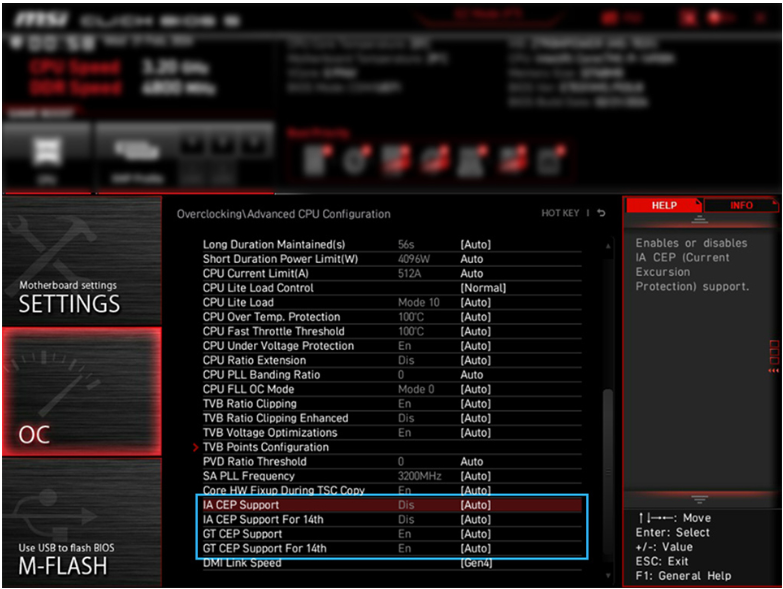
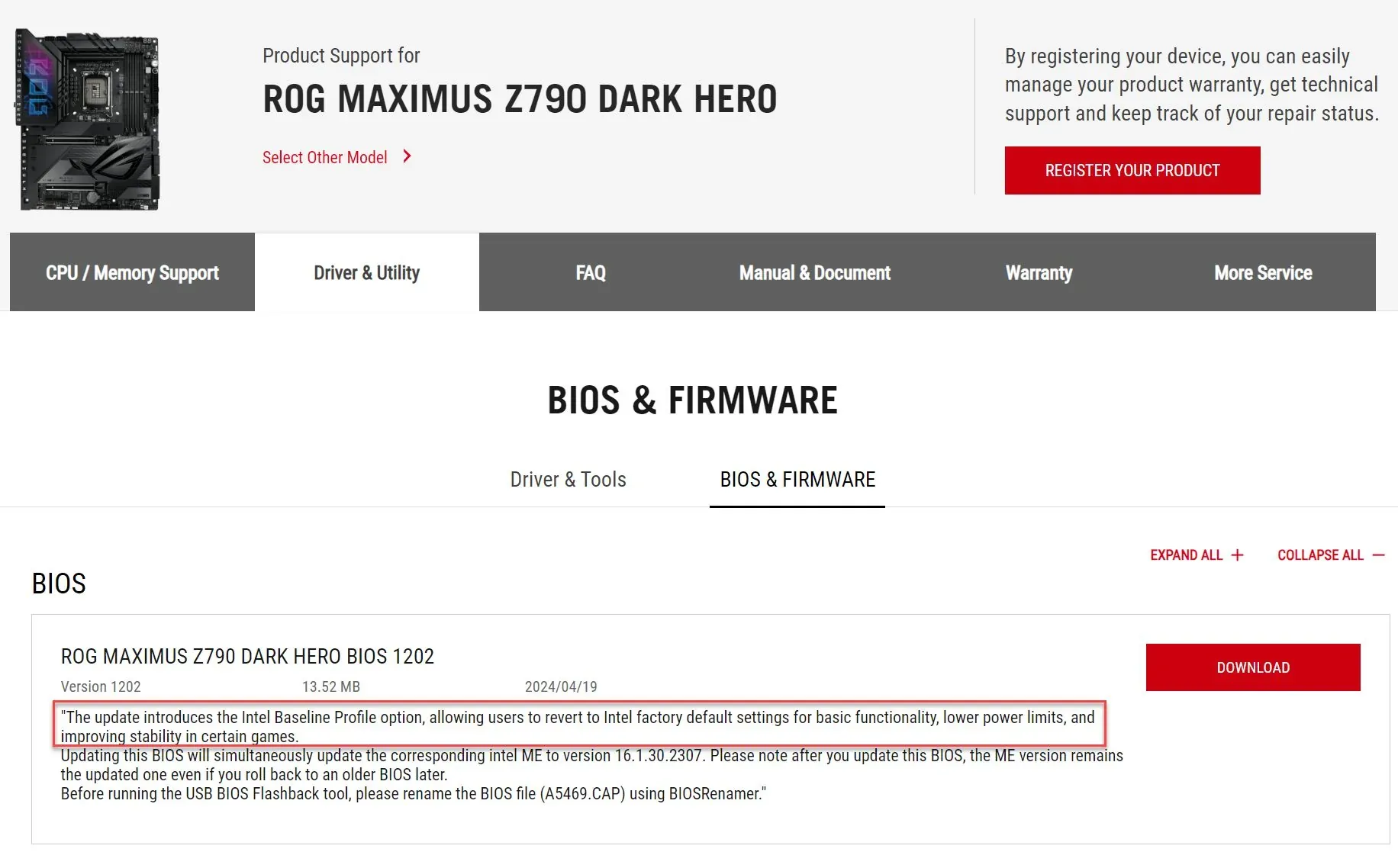



 ...Curry's (UK pc outlet) or some other large pc system distributor recently, would there be a re-call of their systems fitted with these CPU's, or if a future 'Fix' would be offered (especially if the system was still under some kind of warranty). I can see some skulduggery happening over this, and a good portion of end users loosing out.
...Curry's (UK pc outlet) or some other large pc system distributor recently, would there be a re-call of their systems fitted with these CPU's, or if a future 'Fix' would be offered (especially if the system was still under some kind of warranty). I can see some skulduggery happening over this, and a good portion of end users loosing out.  ... (to anybody really btw.)...I've just noticed that the Ryzen 9 7900X3D cpu is about the same price at the moment as the Ryzen 7 7800X3D ?, I'm just wondering which one to use in my next build. I've very briefly compared the two in online benchmark information sites this morning but I'd like to know what the thoughts of some people who are here think please!
... (to anybody really btw.)...I've just noticed that the Ryzen 9 7900X3D cpu is about the same price at the moment as the Ryzen 7 7800X3D ?, I'm just wondering which one to use in my next build. I've very briefly compared the two in online benchmark information sites this morning but I'd like to know what the thoughts of some people who are here think please!